






Large Language Models (LLMs) are powerful general-purpose systems. But once they enter real workflows, the same question comes up again and again: should we fine-tune the model?
Fine-tuning can improve accuracy, enforce structure, or adapt a model to your domain. But it can also increase cost, introduce technical debt, and reduce flexibility. In many situations, lighter methods like prompt engineering or Retrieval-Augmented Generation (RAG) give you better results with far less overhead.
Here’s a clear view of when fine-tuning helps, and when it creates more problems than it solves them.
What Fine-Tuning Is (and Isn’t)
Fine-tuning means continuing the training of a pre-trained model using a smaller dataset tailored to a specific task, format, or tone. It adjusts the model’s behavior, nudges it toward a defined structure, or adapts it to repeated patterns in your data.
It’s common to assume fine-tuning is the fastest path to model optimization: add examples, start training, get a better model. But the trade-offs are real. Fine-tuning can impact latency, cost, update cycles, reproducibility, and even general performance. Done poorly, it can degrade the model.
Understanding those limits is a must before committing to any tuning pipeline.
If you’re exploring alignment or post-training strategies beyond fine-tuning, we break down modern methods like DPO, RLAIF and GRPO in our article on alternatives to RLHF for post-training optimization.
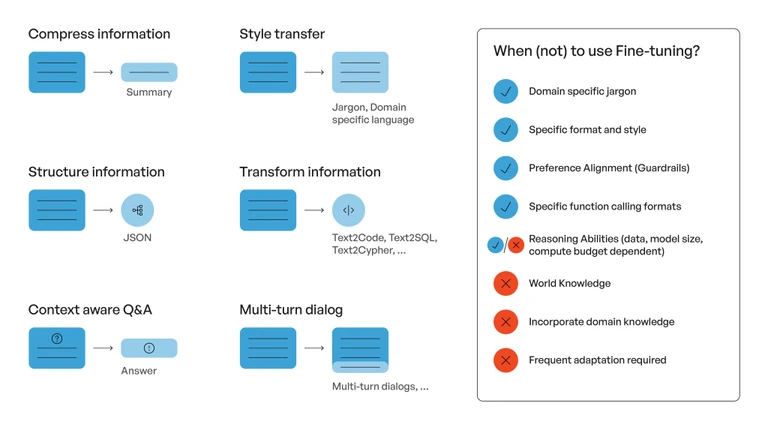
When Fine-Tuning Makes Sense
Fine-tuning works well in situations where the goal is narrow, measurable, and stable.
1. The task is tightly scoped
Fine-tuning excels when the output space is predictable and the success criteria are clear.
Examples:
- Classifying support requests into predefined categories
- Ranking internal search results
- Generating SQL queries for a known schema
These use cases provide clean, structured input–output pairs and reliable ground truth, making fine-tuning straightforward and measurable.
2. You need consistent, structured outputs
Some workflows demand strict formats—XML, JSON, domain-specific templates, or multi-field responses—where one small deviation breaks the process.
Fine-tuning helps when:
- Prompt engineering still produces inconsistent formatting
- The structure must remain stable across thousands of calls
- The model must generalize the pattern with little supervision
Examples:
- Producing API calls with dozens of nested fields
- Generating compliance documents with rigid structure
- Encoding reasoning steps into machine-readable formats
3. Your domain uses specialized language or tone
Models often struggle with domain-specific vocabulary or industry-standard phrasing. Fine-tuning helps the model internalize the expected style, whether clinical, legal, regulatory, or financial.
Examples:
- Medical report summaries using accepted shorthand
- Legal document drafting requiring specific clauses
- Customer support responses aligned with a company’s tone
If the dataset provided is of high quality and representative, then fine-tuning will work well.
When Fine-Tuning Isn’t the Right Approach
Fine-tuning is often overused. In many cases, it introduces unnecessary complexity or breaks more than it fixes.
1. You want to add or update knowledge
Trying to “teach” an LLM new facts through fine-tuning is unreliable. It can actually:
- Clash with the model’s existing world knowledge
- Produce unpredictable overrides
- Make updates difficult when information changes
- Lead to catastrophic forgetting
If you need fresh or evolving knowledge, use RAG instead. Feeding the model updated context at inference time is more stable, cheaper, and easier to maintain.
2. Your use case is broad or constantly evolving
If your application involves open-ended interactions or multiple task types, fine-tuning can limit the model.
Example: Fine-tuning a chatbot on customer support tickets may make it worse at writing emails, answering coding questions, or handling edge cases.
Another example?
Fine-tuning a model on analytics dashboards to “speak BI language” may reduce its ability to reason about unstructured data or perform broader analysis tasks that weren’t part of the training set.
Unless the task is stable and narrow, sticking to prompting or RAG avoids locking the model into a narrower skill set.
3. You lack the infrastructure or data for safe fine-tuning
Fine-tuning requires more than GPUs. You need:
- Clean, labeled datasets
- Versioning, testing, and repeatable pipelines
- Clear evaluation metrics
- Monitoring and rollback capability
Without this foundation, fine-tuning experiments become hard to trust and even harder to maintain.
What You Need to Fine-Tune Successfully
When fine-tuning is the right choice, three ingredients matter more than anything else.
1. Solid infrastructure
This includes:
- Scalable training environments
- Storage for checkpoints and logs
- Workflow orchestration (MLflow, W&B, etc.)
- Secure data pipelines
Even small models require iteration. Plan for it.
If you’re evaluating training platforms, our comparison of Databricks, SageMaker, and Colab for LLM optimization helps clarify the strengths and limits of each environment.
2. High-quality data
Your dataset defines the behavior you’re training into the model. It must be:
- Clean and consistent
- Representative of the desired output
- Free from contradictory examples
- Large enough to reveal patterns clearly
Evaluation and hold-out test sets must be separate from the training corpus to avoid false confidence during validation.
3. Clear, measurable objectives
Fine-tuning without metrics leads to subjective or unstable results.
Examples of solid metrics:
- Accuracy on a constrained classification task
- Reduction in formatting errors
- F1 score for extraction tasks
Automated evaluation strengthens repeatability, while human review covers the subtleties automation misses.
Alternatives to Fine-Tuning
Before reaching for GPUs, ask whether a simpler method can achieve the same outcome.
Prompt Engineering
Often enough for:
- Tone adjustments
- Small behavioural changes
- Logical structure through step-wise prompting
- Few-shot examples that demonstrate the pattern
With high-end models, prompt engineering frequently competes with fine-tuning on performance.
Retrieval-Augmented Generation (RAG)
Ideal when:
- Knowledge changes often
- You want transparency and source traceability
- You need modularity across documents or systems
RAG avoids model drift and keeps information fresh without retraining.
If you’d like to see how RAG works in production for customer support, check out our case study: Empowering Customer Support with Agentic AI and RAG.
Tool Use and Function Calling
If the model needs to interact with external systems, don’t fine-tune the logic—teach it to call the right function. Modern LLMs handle this well with the correct schema.
A simple decision framework:

If uncertainty remains, start with prompt-based methods—they’re cheaper, reversible, and faster to iterate on.
Final Thoughts
Fine-tuning is a powerful tool… only when used intentionally.
In many real deployments, requirements evolve quickly, knowledge must stay fresh, and iteration speed matters. In those cases, RAG, prompting, and function calling are often more flexible and far easier to maintain.
The right approach depends on your task, your data, and your infrastructure.
Fine-tuning shouldn’t be the default. It should be a deliberate choice, backed by clear goals, and the right conditions.



