






Reinforcement learning from human or AI feedback (RLHF/RLAIF) has shaped some of the most widely used language models today. From OpenAI’s ChatGPT to early versions of Anthropic’s Claude, reinforcement learning has played a key role in aligning model behavior with human intent.
But it’s not the only option. As new use cases emerge, more teams are exploring alternatives to RLHF for post-training optimization that offer faster convergence, fewer moving parts, and clearer behavior.
Above all, the latest generation of LLMs that have been post-trained with reinforcement learning excel at reasoning tasks if they are combined with test time scaling during model inference.
But alignment is evolving. RLHF is costly, slow to scale, and often difficult to interpret. Newer methods – like Direct Preference Optimization (DPO), Reinforcement Learning from AI Feedback (RLAIF), and Guided Reward Propagation Optimization (GRPO) – are now proving just as effective in many scenarios, often with simpler architectures and fewer dependencies.
As a result, Reinforcement Learning is now considered the central force behind impressive human like reasoning capabilities. While Reinforcement Learning served as a final polishing step for the first generation of LLMs like ChatGPT, today’s models are placing reinforcement learning at the core of their optimization pipelines.
Recent examples include Kimi K2, which introduced a Self-Critiqued Policy Optimization approach, and Qwen 3, which uses a technique called Group Sequence Policy Optimization (GSPO). OpenAI’s O3 models are advancing toward verifiable reward signals for better alignment control, while Claude 4 from Anthropic has shifted to Reinforcement Learning from AI Feedback (RLAIF) to scale preference learning without human annotation.
This article outlines where RLHF still applies, how the alternatives compare, and what to consider when choosing your post-training optimization strategy.
The Limits of Reinforcement Learning from Human Feedback (RLHF)
RLHF fine-tunes a model by optimizing it against a reward function trained on human feedback. Typically, this means:
- A reward model is trained on human comparisons (e.g., “Response A is better than B”).
- The model is then optimized using a reinforcement learning loop, usually with Proximal Policy Optimization (PPO).
This setup has real benefits, but also serious drawbacks:
- Labor-intensive: Requires large volumes of annotated data from human labelers.
- Opaque: The reward model can become a black box, encoding inconsistencies or bias.
- Sensitive: PPO is notoriously tricky to tune, especially in large-scale settings.
- Sparse feedback: Reward signals may not generalize well to new prompts or domains.
As teams seek faster iteration and more predictable outcomes, other techniques are stepping in.
Introducing the Direct Preference Optimization (DPO) Technique
DPO simplifies alignment by cutting out the reward model altogether. Instead, it uses pairwise preferences to adjust the model directly.
How it works
- Each training example includes a prompt, a preferred output, and a rejected output.
- The model is optimized to increase the likelihood of preferred completions while staying close to its original behavior.
- This is done using a log-likelihood ratio loss regularized by a KL divergence.
Why teams are using it
- No reward model: Reduces complexity and training steps.
- More stable: Uses a supervised-style loss function, which is easier to train and debug.
- More interpretable: You can directly observe which outputs were nudged and how.
When to use DPO
- You have access to preference-labeled data (from humans or proxies).
- You want fast iteration and minimal engineering overhead.
- Tasks include chat alignment, summarization, or instruction following.
Introducing the Reinforcement Learning from AI Feedback (RLAIF) Technique
RLAIF replaces human preference collection with a feedback model that scores outputs automatically. That model may itself be trained on human preferences, but once in place, it enables large-scale preference generation at low cost.
How it works
- The feedback model ranks outputs or gives scores (e.g., for helpfulness, formatting, tone).
- These scores can be used to train a reward model (as in RLHF), or as input to DPO-style training.
What makes it attractive
- Scales easily: Once the feedback model is ready, you can generate thousands of comparisons in minutes.
- Cost-efficient: No need to rely on human annotation for every iteration.
- Flexible: Works with different alignment techniques.
Risks to watch
- Feedback quality depends on the model used—it may replicate bias or amplify errors.
- Mistakes compound if synthetic data isn’t filtered or validated.
When to consider RLAIF
- You need large-scale preference data fast.
- Human annotation isn’t feasible (e.g., expert domains, coding).
- You already have a well-performing base model or proxy rater.
Introducing the Guided Reward Propagation Optimization (GRPO) Technique
GRPO is a newer method designed to help models improve on tasks that require structured reasoning or multi-step outputs. It works without a reward model or PPO—and instead guides optimization across the entire sequence.
What sets GRPO apart
- Rather than assigning a single reward to an output, GRPO distributes it across tokens or reasoning steps.
- It’s verifiable reward functions make Reasoning steps more transparent and steerable.
- The model learns not just what to output, but how it got there.
- This improves internal consistency and reasoning quality.
Strengths
- No reward model needed.
- Works well with synthetic feedback or weak supervision.
- Particularly good for logic, math, coding, and chain-of-thought tasks.
Use it when…
- Your task involves structured or step-by-step reasoning.
- You have a verifiable output that can be evaluated using rules.
- You want outputs that are not only correct, but explainable.
- You are working with limited or noisy preference data.
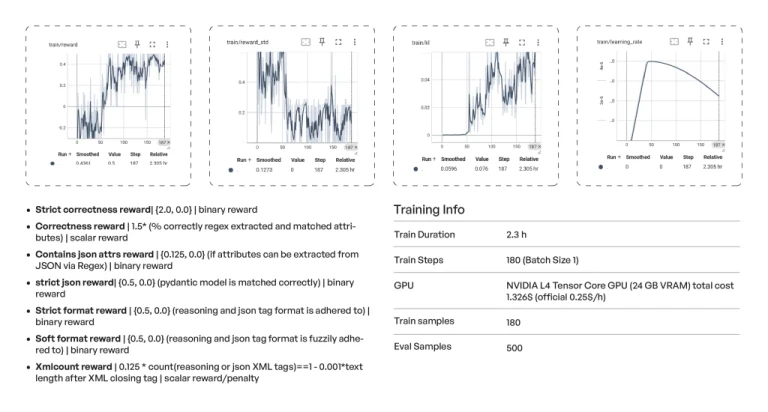
TensorFlow metrics of a representative small-scale GRPO fine-tuning experiment. Structured constraints guide output quality without human-labeled rewards.
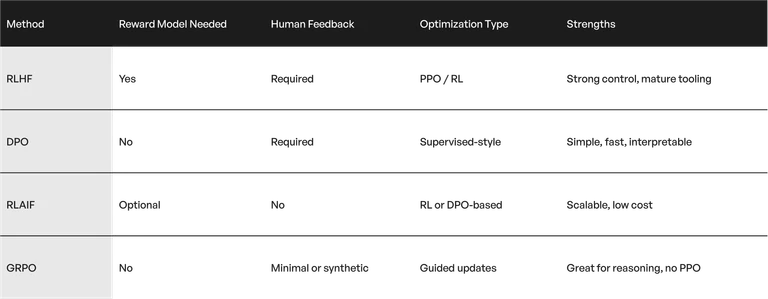
Comparing the Methods: RLHF and its Alternatives
Here is a quick side-by-side view of the four methods:
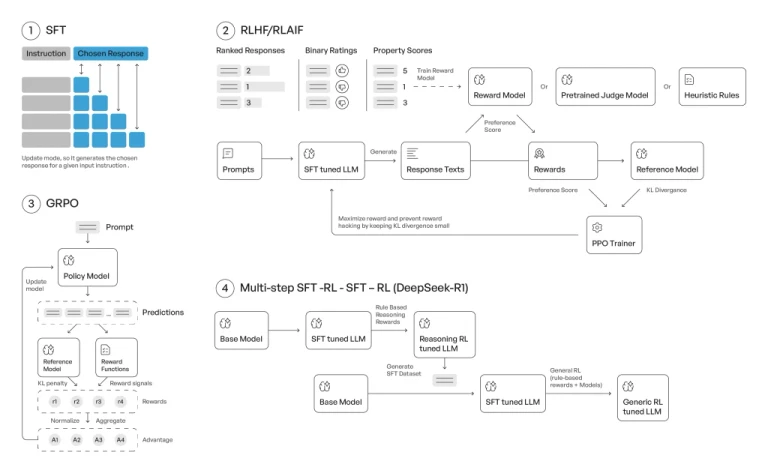
Learning pathways: how different alignment techniques structure model optimization.
Choosing the Right Optimization Strategy
Not every project calls for the same alignment technique. The right optimization method depends on the type of task you are solving, the data you have (or can generate), and the resources available to your team.
Below are a few typical scenarios to help guide your decision.
Use RLHF if:
- You have the infrastructure and budget for multi-stage training.
- You need tight control over generation (e.g., safety, tone).
- You are building on established benchmarks or want compatibility.
Use DPO if:
- You already have labeled preference pairs.
- You want a leaner, simpler pipeline.
- You need stability and speed.
Use RLAIF if:
- Collecting human preferences is too costly or slow.
- You want to experiment rapidly with synthetic datasets.
- You trust your proxy feedback model.
Use GRPO if:
- Your task involves multi-step generation or intermediate reasoning.
- Your task generates verifiable outputs or verifiable reasoning steps.
- You prefer a lightweight training loop.

There is no one-size-fits-all answer. Each method offers trade-offs, and in many cases, a combination of approaches will deliver the best outcome. What matters most is building a pipeline that’s stable, reproducible, and grounded in the realities of your task and infrastructure.
Future Outlook
We are seeing a shift from complex, black-box optimization pipelines toward leaner, more interpretable strategies. Teams increasingly favor alignment methods that:
- Work with limited human input
- Allow for better debugging and iteration
- Match compute constraints in real-world settings
Expect more hybrid approaches – using DPO with synthetic preferences, or applying GRPO after an initial supervised round. Tooling is also improving, making these alternatives easier to implement.
Takeaways:
RLHF helped shape the first wave of aligned language models. But there are alternatives to RLHF for post-training optimization. Techniques like DPO, RLAIF, and GRPO bring faster training, fewer dependencies, and more transparency into the fine-tuning process.
Choosing the right method depends on your task, your data, and your constraints.
In many real-world scenarios, teams are already finding that these newer approaches offer better control and faster results – without compromising on quality.
Want the full benchmark, platform comparison, and tool breakdown?
Download our white paper: Mastering the Last Mile: Cross-Platform Comparison of LLM Post-Training Optimization


