



Most developers do not think about the environmental impact of the code they write. But every instruction, loop, and function call has a cost.
Green Coding starts with writing Python that runs cleaner – not just faster. At its core, it means writing code that minimizes energy and resource consumption.
Throughout this article, we’ll often focus on code efficiency as a key aspect of sustainability. Our goal is to bridge Python’s ease of use with performance and sustainability.

Python as an Interpreted Language
Python is widely appreciated for its simplicity and readability, making it a popular choice for rapid development and easy maintenance. Its interpreted nature allows developers to test and debug code quickly, as it executes line by line at runtime.
However, this convenience comes at a cost. Unlike compiled languages such as C or Java, which are transformed into native machine code before execution, Python relies on an interpreter to run code at runtime.
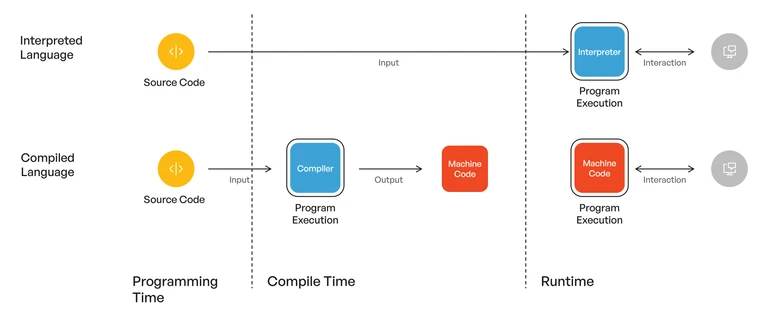
The image presents an idealized and simplified side-by-side comparison of interpreted and compiled programming languages. It illustrates the flow of execution for each type, showing how source code is processed differently in each case.
- Interpreted languages are typically slower because they translate code into machine instructions at runtime, introducing overhead during execution.
- Compiled languages, in contrast, are translated into machine code ahead of time, allowing for faster and more efficient execution directly on the hardware.
Although Python includes a compilation step to bytecode, it is still considered an interpreted language due to its runtime execution model. This model, while flexible, can be less energy-efficient compared to compiled alternatives. Python’s dynamic typing and high-level data structures, while boosting productivity, can further reduce execution speed.
Despite these limitations, developers can adopt various strategies to improve Python code for better performance and sustainability. By applying best practices and leveraging Python’s strengths thoughtfully, it’s possible to reduce environmental impact while maintaining the language’s development advantages.
Practical Guidelines for Green Coding with Python
Efficient code not only benefits the environment but also improves user experience. Here are some key considerations for Green Coding with Python:
Focus where it counts
Green Coding with Python involves understanding execution patterns, profiling code, and strategically optimizing areas that contribute the most to resource consumption. Rather than optimizing every line or function indiscriminately, we strategically identify areas that significantly affect execution time and resource utilization. One can differentiate two common scenarios of such code:
- There is a specific function within your code that takes a substantial amount of time to execute compared to other code.
- There is a specific code section which is executed very often. Even seemingly minor optimizations can have a substantial effect when applied to frequently executed code.
Therefore, we should focus on improving efficiency in areas like that. By measuring execution times, you gain insights into which parts of your code contribute most to energy consumption. Once identified, you can focus on making these sections more efficient.
As a practical example for the first scenario, consider a data analysis application. Suppose there is a function responsible for processing large datasets to generate statistical summaries. This function might involve complex calculations and data transformations, making it significantly slower than other parts of the application. It makes sense to concentrate on that function for code optimizations.
For the second scenario, consider a web application. The code responsible for handling HTTP requests and serving responses is likely to run frequently. By optimizing this part of the application — whether through caching, algorithmic improvements, or better data structures — we can achieve significant resource savings. Every processed request benefits from these optimizations, making them worthwhile even if they seem small individually.
Knowing where to start with optimization in theory, we still need to locate those parts in practice.
Find the bottlenecks
Profiling is the process of systematically analyzing your code to understand its behavior and performance characteristics. In Python, cProfile is a commonly used module for analyzing your code execution characteristics. It helps you identify bottlenecks by providing detailed reports on the function calls made during the execution of a program.
While there are other profilers which might be more fine-grained or with another focus (e.g. line_profiler or memray), cProfile is a Python standard library (you don’t need to install it) and thus a good start for a high-level view. It gives you an overview of the time spent in each function. You can use it as follows:
import cProfile import pstats from time import sleep def func1(): sleep(0.1) # placeholder for code which needs computation time def func2(): sleep(0.2) # placeholder for code which needs computation time def main(): for _ in range(3): func1() func2() # Profile main-function and load, sort and print statistics cProfile.run("main()", "profile_output") stats = pstats.Stats("profile_output") stats.strip_dirs().sort_stats("cumtime").print_stats() # Output (shortened): # ncalls tottime percall cumtime percall filename:lineno(function) # 1 0.000 0.000 0.901 0.901 my_app.py:16(main) # 6 0.901 0.150 0.901 0.150 {built-in method time.sleep} # 3 0.000 0.000 0.600 0.200 my_app.py:12(func2) # 3 0.000 0.000 0.300 0.100 my_app.py:8(func1)
You will get a table showing how many times each function was called and how much time each one took. However, remember that cProfile can sometimes introduce overhead, which might affect the timing results.
For an even simpler approach, if you are interested in the timing of only one specific function, timeit is a good choice which also is a Python standard library. The following example shows its usage.
from timeit import timeit duration = timeit(lambda: my_func(42), number=100) print(f"100 executions needed: {duration} seconds")
Some best practices for code profiling in Python include:
- Focus on hotspots: Prioritize optimization efforts on parts of the code that consume the most time.
- Profile in a realistic environment: Ensure that the profiling is done under conditions that closely mimic the production environment.
- Avoid premature optimization: Don’t improve before profiling. Make data-driven decisions based on profiling results.
- Iterative profiling: Profile, improve, and then profile again to measure the effect of your changes.
However, there are also pitfalls to avoid:
- Over-reliance on micro-optimizations: Small tweaks might not lead to significant improvements and can make the code harder to maintain.
- Ignoring I/O operations: Sometimes, the bottleneck is not in the CPU but in I/O operations. Profiling should also consider file reading/writing, database access, and network communication.
- Neglecting algorithmic complexity: Profiling might point to slow functions, but the real issue could be the choice of algorithm or data structure.
Now that we know where to improve, what are the means to do so?
Use existing packages
The use of existing Python packages to solve common problems is mostly beneficial due to their speed and optimization. We usually can assume that because they are developed and maintained by experienced contributors, often open-sourced or backed by organizations, and are continuously improved over time based on community feedback, performance benchmarks, and real-world usage.
Here are the key arguments focused on Green Coding:
- Optimized Algorithms: Many Python packages contain algorithms that have been refined and improved over time by a community of developers. These algorithms often perform better than what a single developer could implement on their own.
- Compiled Machine Code: Some Python packages use machine code or interfaces to libraries written in compiled languages like C. This results in a dramatic increase in performance.
- Energy Efficiency: Efficient code translates to less CPU usage, which in turn means less energy consumption. By using well-established packages, developers ensure that their code runs faster, thus aligning with the principles of Green Coding.
Thenumerical computing and array manipulation package NumPy is a good example for the above arguments as it embodies the power of community-driven optimization, having been refined over years by countless developers who contributed high-performance algorithms and reliable features. Its core operations are executed in compiled C and Fortran code, ensuring exceptional speed and energy efficiency compared to manual Python implementations.
Of course, it’s impossible to know about every package out there. So, whenever you encounter a non-trivial problem that you think others may have experienced, you should get into the habit of searching the web for a suitable Python package.
Improve algorithmic efficiency
The following list contains some techniques and concepts that can help to make Python code more efficient. This list is neither exhaustive nor in any specific order.
Caching: Use caching when data is expensive to compute or fetch and is reused frequently, as it significantly reduces processing time and energy consumption. It’s important because it minimizes redundant operations, leading to faster response times and lower carbon footprints in software systems.
But be aware that caching can have negative effects when used inappropriately. Cache only what’s necessary and set appropriate expiration policies to avoid stale data and excessive memory usage (e.g., have a look at Python’s lru_cache).
from functools import cache @cache def fibonacci(n): if n < 2: return n return fibonacci(n-1) + fibonacci(n-2)
Dynamic Programming: Use memoization or tabulation to avoid redundant computations, reducing CPU cycles. Additionally, prefer iterative solutions over recursion when possible.
The following example shows how to make use of dynamic programming through the generator function “fib_generator”, which builds each Fibonacci number iteratively using previously computed values, avoiding redundant recalculations. This efficient reuse of subproblem results (i.e., storing and updating “a” and “b”) exemplifies the core principle of dynamic programming.
def fib_generator(n=-1): a, b = 1, 0 while n != 0: a, b = b, a + b yield b n -= 1 # is there a fib number divisible by 10 among first 100 fib numbers? div_10 = any(x % 10 == 0 for x in fib_generator(100)) # True # calculated only first 15 fib numbers, not 100!
Furthermore, thanks to the generator logic, only the results that were iterated over were calculated, rather than all 100 Fibonacci numbers.
Suitable Data Types and Structures: Choose the right algorithms and data structures. When dealing with a lot of items, opt for sets over lists when searching for elements (sets have faster lookup times).
if item in my_set: ... # fast search if item in my_dict: ... # fast search if item in my_list: ... # inefficient search
Use generators and list comprehensions to minimize memory usage.
squares_list = [x**2 for x in range(100)] squares_generator = (x**2 for x in range(100)) square_mapping = {x: x**2 for x in range(100)}
I/O Operations: Reading from or writing to files, databases, or network sockets can be resource-intensive. Minimize unnecessary I/O calls, use buffered I/O, and consider asynchronous programming (with asyncio) to handle I/O efficiently.
Recursive Algorithms: Recursive functions can lead to excessive memory usage due to function call overhead and stack frames. Iterative approaches may help reduce resource consumption.
String Manipulation: String concatenation within loops can be slow. Instead, use join for better performance.
concatenated = ", ".join(my_big_item_list)
Also, consider using regular expressions judiciously, as they can be computationally expensive. Avoid them for simple tasks like checking substrings or splitting strings, as they can be slower and harder to read.
Memory Leaks: Be cautious of memory leaks caused by objects that are not properly deallocated. Use context managers (“with” statements) for file handling and ensure timely garbage collection.
Database Queries: If your code interacts with databases, improve SQL queries, use indexes, and minimize unnecessary data retrieval.
Just-in-time compilation
Just-in-time (JIT) compilation is an important technique in Python that can significantly improve performance by translating code into machine-level instructions at runtime. Unlike the traditional method of code execution by the Python interpreter, JIT compilation translates frequently executed code into native machine code during execution. This can lead to improved performance, particularly for compute-intensive tasks.
While JIT compilation can lead to performance gains, its effect on energy consumption is more nuanced. Although faster execution reduces the total energy consumed by a program, the compilation process itself also consumes resources. The overall benefit therefore depends on the nature of the workload and how effectively the JIT compiler optimizes the code.
Additionally, JIT compilation can sometimes reduce memory usage by eliminating redundant operations or optimizing data structures at runtime. However, this is not guaranteed and varies depending on the implementation and the specific code being executed.
Consider the following example of Numba, a famous JIT compilation package for Python:
import numpy as np from numba import jit @jit def go_fast(a): # Function is compiled to machine code when called the first time trace = 0.0 # assuming square input matrix for i in range(a.shape[0]): # Numba likes loops trace += np.tanh(a[i, i]) # Numba likes NumPy functions return a + trace # Numba likes NumPy broadcasting
Numba accelerates the “go_fast” function by compiling it to native machine code at runtime, significantly reducing execution time for numerical computations. It enables fast execution of loops and NumPy operations without requiring manual optimization or rewriting in a lower-level language.
Takeaways (for you and the planet)
Green Coding (with Python) is more than a trend—it’s a responsibility. As developers, we have the power to influence the environmental footprint of the digital world through the choices we make in our code. Python, despite its interpreted nature and performance trade-offs, offers a rich ecosystem and powerful tools that, when used thoughtfully, can lead to highly efficient and sustainable software.
By profiling code to identify bottlenecks, leveraging specialized libraries, choosing the right algorithms and data structures, and applying techniques like caching and JIT compilation, we can significantly reduce energy consumption and improve performance. These practices not only benefit the planet but also improve the scalability, maintainability, and responsiveness of our applications.
Beyond the theory, our team is trained to apply these best practices in real client projects where performance and sustainability go together. After all, sustainable development is a journey, not a destination. Every well-written function is a step towards more responsible, sustainable tech solutions.


